
Transcription: Reverse Engineering Intelligence
To make artificial intelligence, we may just be reverse engineering natural intelligence.

Hello, and welcome to Transcription, a weekly overview of research happenings in biotechnology and immunology! Subscribe to stay informed and support my work:
Reverse Engineering Intelligence
Artificial intelligence has been a rather hot topic these last few years. But the seeds for AI’s insane growth were sown decades ago in the 1980s when discoveries enabled the sector to emerge from its “AI winter”. And even further back to the 1940s when Alan Turing and other mathematicians developed computers and algorithms for encrypting messages, and for cracking enemy’s encryptions.
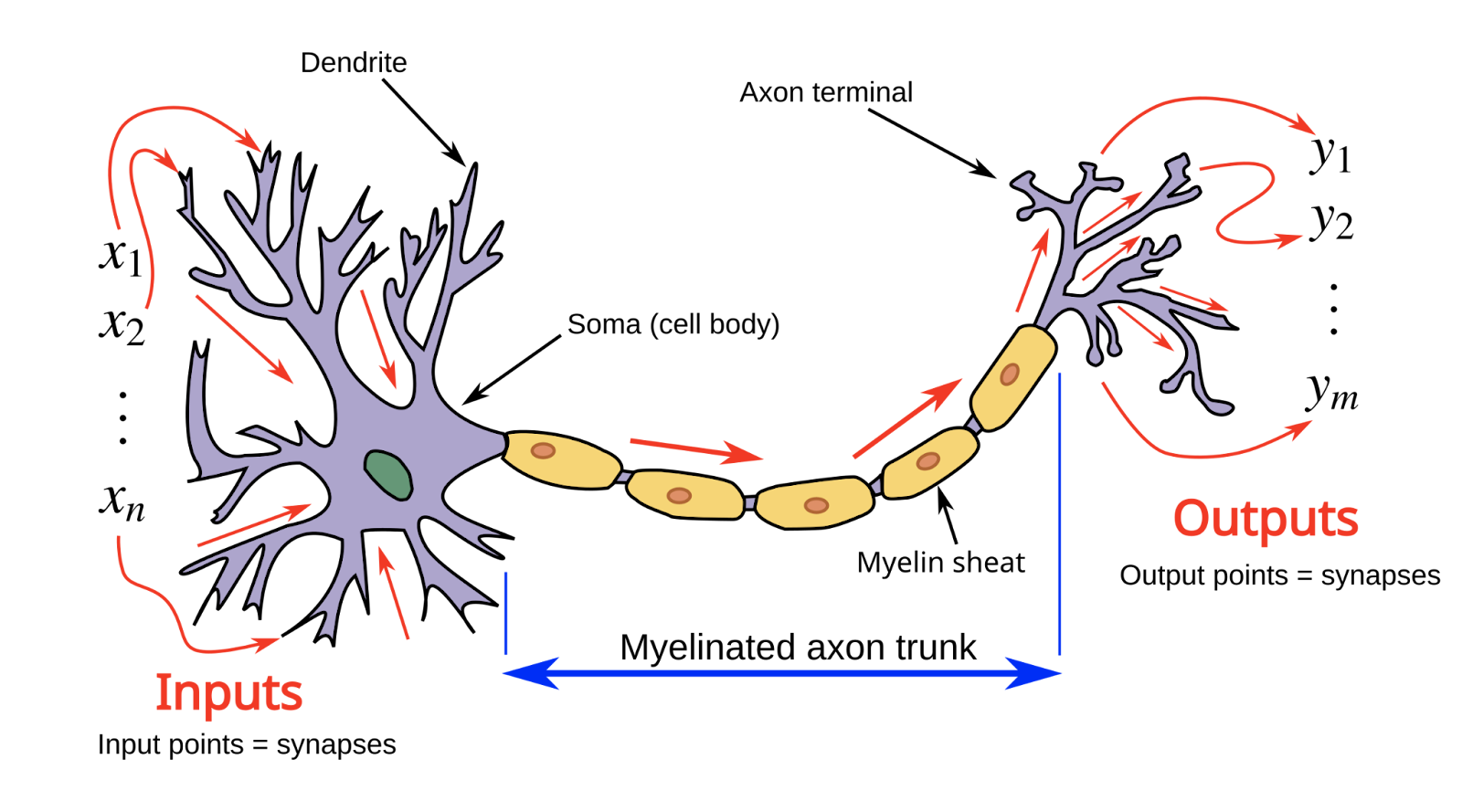
One major inspiration for modern systems is how our brain stores memories and processes information. And indeed one of the earliest discoveries that enabled modern artificial intelligence systems was the perceptron.
A perceptron is a mathematical representation for a human neuron. Our neurons are constantly communicating with their neighbors, passing messages to each other via small electrical signals. A single neuron will take in a bunch of these signals at once, and decide whether to pass that message along to their nearby friends downstream that signal. Pretty simple.
Amalgamate billions of these neurons together, along with decades of interacting with and learning from its environment, and you get… consciousness? Neurons studying and writing about themselves? Biology is weird.
{kind=link}
Mathematicians during and after World War 2 wanted machines to do math for us, for instance to crack encrypted messages. Good idea! And they took inspiration from our beautiful biological neurons to do so.
The perceptron tries to replicate the neuron's behavior mathematically. The inputs and outputs, rather than electrical signals, are just numbers. The inputs are aggregated by a weighted sum, and if it's greater than some threshold number then the perceptron’s signal will output a 1. If it's less than that threshold, it will send down a 0.
Perceptrons are at the center of modern artificial intelligence. They are the unit cell - the neuron - of the artificial intelligence algorithms that power ChatGPT.
The perceptron does an OK job. But it's far from the power of a biological neuron. Researchers attempted a head-to-head comparison: take the activity of a single neuron, and see if a perceptron could replicate its behavior. In a lab, they gave a single neuron a bunch of electrical signals and monitored whether it propagates the messages or not. They took these measurements, and tested whether the perceptron could learn to activate under the same conditions as the biological neuron. And it couldn’t1. In fact, they needed to aggregate almost 900 perceptrons together. All to replicate the activity of a single biological neuron!2 No wonder we’re so special.
With all the hype in developing artificial intelligence, many researchers are studying how our brains function to better replicate their behavior in computer algorithms. A lot of this work is concentrated in the design of these artificial intelligence networks, rather than on making the individual perceptrons more capable. And it makes sense! Join many perceptrons together in a neural network, and these simple machines can create marvels like ChatGPT or image generation tools like Midjourney. There is still room to grow in artificial intelligence system design, too. Zooming out from the individual neuron, there are other clear differences between our brains and modern artificial intelligence systems.
There is a clear organization to our brains. Unlike artificial intelligence algorithms, which are just a black box of perceptrons with limited organization or individual purpose, our brain's development is consistent with distinct features. There is a hippocampus in the center, which consolidates many short-term memories into fewer long-term memories. Our cerebellum at the back is the movement center, controlling walking and balance. Connecting our brain to our spinal cord, the medulla oblongata regulates vital functions like breathing, heartbeat, blood pressure, and our circadian rhythm (the sleep-wake cycle). Our brains are not black boxes of information. They are complex planned cities of individual agents with distinct jobs.
Our brains self-organize into intelligent systems far more capable and complex than cutting-edge artificial intelligence programs harnessed within hundred-million-dollar data centers. We just have to feed it, sleep enough, and teach it by learning new stuff. If we could crack the code of how our brains’ organization creates intelligent systems, we could design far more powerful and efficient computer systems to replicate that intelligence.
The challenge is that interpreting these complex systems is a huge challenge. It's not like our neurons are labeled or have a manual or instruction booklet. They just kind of do their thing?
There is a lot for artificial intelligence algorithms to learn from our brains. But there is perhaps even more for us to learn about our own brains. And something we do not understand well is how our brains store and process information. How does our brain hold a memory? Or process the information given by our five senses?
For instance, how do we process and recognize scents? An odor is, fundamentally, a chemical that binds to receptors on cells in our nose. These nasal cells are a special type of neuron called olfactory nerves. The signal from those nerves is sent to the rest of our brain. That’s all par for the course. But how do we remember different smells? How do we store that information to access later? How do we decide if we like a given smell?
Researchers at the University of Bonn in Germany were curious, so they implanted electrodes in people’s brains. They gave them a smell test with a collection of smelly things: garlic, bananas, cinnamon, coffee, liquorice, etc. And they collected electrical data with their electrodes to see which areas of the brain were messaging each other via electrical signals in response to the odors.
A region of the brain known as the piriform cortex stores the identity of odors. Which makes sense, because it sits close by our nose.
But how our brains actually process this information is more interesting. It turns out the amygdala, a region of the brain associated with processing emotions, determines the subjectivity of different smells. It figures out whether we like a particular smell or not.
And then they gave these patients a test. Or rather, their neurons are a test. They first showed them images of their different scents, followed by the scent itself. For instance, a photo of a pineapple followed by smelling a pineapple. The patients would go through a stack of around 14 photos, and were then given the scents. They tried to guess which scent they were smelling. Was it an apple or a banana? Or garlic?
They found that the hippocampus region in the center of our brains is involved in identifying the scent. The neurons right by our nose communicate with this region much further away to determine what is creating the scent, helping us identify if it is something dangerous like smoke, or if it's something yummy like an orange.
And then they did the opposite. Give the patients a collection of smells, then show them photos of those smells. And they measured which neurons were activated in response to the different smells and photos. What they found was that the same odors encoding smelly information in the piriform cortex right by our nose were activated just by seeing a photo of a smell. For instance, they found a single neuron that signaled when people smelled cinnamon, and then showed them an image of cinnamon, and that same neuron signaled again. And this was super specific to the particular smell. That same neuron did nothing in response to smelling bananas, or seeing a photo of bananas.
In essence, a single neuron responsible for processing the smell of bananas also helps process visual information for bananas. The way we process information across scent and sight is coordinated across our brain, with neurons from the piriform cortex in the very front of our brains coordinating with their colleagues in the hippocampus deep in the center of our brains. Whether this is also true of cells in the visual cortex of our brain that are connected to our eyes via the optic nerve remains to be studied. But it seems that our brains store the information of scents in a similar way to how we store visual information, crafting abstract visual representations of the smell.
Maybe you wonder why this matters? Well, misidentifying odors is an early symptom of neurodegenerative disorders like Parkinson’s and Alzheimers. Understanding how we identify odors and how this breaks down can explain how these diseases manifest, and may point to new ways to treat these patients. And, as mentioned above, figuring out how our brain works can make computer algorithms much faster and more efficient. Biological neurons are far superior than current computational ones, and our brains are substantially more energy efficient than power-hungry datacenters to train artificial intelligence algorithms. Replicate how biology creates intelligence, and we can solve this problem while harnessing the benefits of powerful artificial intelligence. And it appears the organization of our brain is tantamount to its intellectual prowess.
In my opinion, the future will contain artificial neuroscientists who train to study, design, and diagnose artificial intelligence systems. These computational doctors will craft the organization of increasingly complicated perceptron networks to unlock their ability to reason through superintelligent problems. For the good of the world. Hopefully.
Intelligent systems are super complex, and our brains are no different.
Do we process smells by seeing them? By generating an abstract image of them in our mind? Apparently, yeah.
Reverse Engineering Data Centers?
Nature is the best inspiration. Perhaps it is the best tool as well. Many companies are turning to biology as a solution for global problems, such as carbon capture, water pollution, and, as mentioned above, intelligent systems.
Now there is an interest in using biology to make more efficient data centers?
Sure, our super-powerful computers can make social media and communicate across the world in milliseconds, or let us watch an endless catalog of media through Netflix or Youtube. But these networks are only that powerful because we control a gargantuan mountain of information and can access it rapidly. Everything on the internet exists because someone put it there. And everything on the internet is stored on a computer somewhere.
Not just in some abstract sense, either. The 1’s and 0’s encoded within computer programs exist in the physical world. Most of that data exists on harddrives, where nanoscale magnets are polarized to the north (encoding a 1) or to the south (for a 0). It can be challenging to actualize this when looking through a screen. But what we type and read and watch and listen to in the digital world is information that is stored in the physical world, somewhere.
Probably a datacenter. These buildings take up a massive amount of electricity and water from their local utility grid. Making more efficient computer algorithms and processing chips could solve this (see above!).
But they also take up a huge amount of space.
The new millenia ushered in the information age. And it is aptly named. It's impossible to exist in today’s society without relying on modern computers. And with that, a lot of things we used to do by hand are now done digitally. Communication, outside of face-to-face conversations, is almost entirely digital. Our photos and videos are digital, shared across networks of people around the world via networks of our friends and families. All these digital interactions create a ton of digital data.
What this means, logistically, is that the amount of data stored around the world has exploded.
Let’s put this into historical perspective. The most notable “datacenter” of the ancient world was the Library of Alexandria. This awesome historical library hosted hundreds of thousands of scrolls containing the information of the era, such as the circumference of the Earth calculated by Eratosthenes of Cyrene, a masterful geographer and mathematician of ancient Greece. These scrolls by some estimates held up to around a terabyte of data in totality3.
Today, we generate around 400 terabytes of data every day. That’s four hundred Libraries of Alexandria a day. But we aren’t constructing four hundred libraries a day?
The difference here is in the information density. A book is a rather obtuse object to store a lot of information. They weigh a lot, are prone to water damage or fire, and take up a lot of space on shelving units. I love books, I swear. But when it comes to storing the information of the world, there are more efficient alternatives.
An 8.5” x 11” sheet of paper can hold around 2,000 characters, where each character can be represented digitally in around 8 bits, or 1 byte. So the information density of a book is around 21.3 bytes per square inch. The hard drives of modern computers and data centers contain around 150 gigabytes per square inch. Or 150,000,000,000 bytes per square inch. That’s seven billion times more information density in computers than in written books.
So we can build one datacenter, capable of storing around ten petabytes of information on these harddrives in roughly the same footprint as the Library of Alexandria. And a single petabyte is a quadrillion bytes.
But the thing is we keep on generating more and more data. Yet the technology that grows the data density of harddrives is plateauing. They aren’t getting much better at storing more data in the same footprint.
It turns out there is something even more energy dense than modern harddrives: DNA.
Since a single DNA nucleotide is so small, 3.4 nanometers in length by 2 nanometers in width, it can hold a ton of information in a relatively small package. Our cells are microscopic, but each holds within them 3 billion molecules of DNA. And indeed the data density of DNA is around 120 terabytes per square inch, nearly a thousand-times more than harddrives!
The challenge is we have to be able to control the information stored in DNA. Our DNA stores the data we need to create all the proteins and whatnot to live and thrive, but not our Netflix shows or Instagram feeds. We need to be able to write this data into DNA to store in, and then read the information to access it via computers.
DNA sequencing has accelerated to a point where billions of bases on DNA can be processed in a matter of minutes. And relatively cheaply, too. So reading DNA is an already solved problem.
But writing to DNA has been a bigger challenge. Modifying the physical DNA molecules to store a sequence is challenging if that sequence is more than a couple hundred molecules. A single movie is billions of bytes, meaning we need to encode billions of DNA molecules in the correct order. If we can’t efficiently encode the information we want to, then using DNA to store our digital data (all 400 terabytes a day) is impossible.
Researchers at Peking University in Beijing and Arizona State University recently unveiled a new method for writing information to DNA. In this approach, they can take information they want to encode (like a photo of a panda!) and generate a DNA sequence that stores that information in its nucleotides. Then, to extract that data, the DNA sequence is read by sequencing machines and decoded, returning the original image of the panda!
What’s new with their approach is they can edit the DNA all at once. Rather than generate each DNA molecule one-at-a-time and stick it on the end, they can start in multiple locations at once, reducing the time it takes to generate long sequences of DNA encoding large files like photos. It’s similar to how our cells copy DNA when they divide. Many enzymes that copy DNA start all at once in various places of our genome, and the final copy is then stitched together from those pieces.
Their new approach can write DNA quickly and accurately. And both are essential if DNA data storage is ever going to supplement (or replace) our existing harddrives. While this is still a nascent technology, the theory is there for DNA to store our growing data stockpiles in a more space efficient manner. And indeed the techniques are there to store videos and recover them, solely from DNA!
Taken together, in the search of ever powerful computer algorithms and data stockpiles needed to train those algorithms, scientists are turning to nature to find how evolution solved both problems. To make artificial intelligence, we may just be reverse engineering natural intelligence.
The main reason, the researchers find, is a class of receptors called NMDA receptors. These receptors enable neurons to respond to messages in a time-sensitive manner. And individual biological neurons can solve XOR problems, while perceptrons can't as they're limited to linear separation planes.
To be fair, they were trying to replicate one of the most complex neurons in our brain: L5 cortical pyramidal neurons. These bad boys connect all 6 layers of the cerebral cortex, the outermost layer of the brain responsible for a lot of abstract reasoning and perception. It wasn’t really a fair fight. But there also isn’t an alternative to perceptrons in artificial intelligence systems, at least today. That’s all they got!
Approximately 700,000 scrolls stored here. Assume each scroll is around 500 pages, with each page around 2,000 characters. each character is around a byte, so 2,000 bytes per page, 1,000,000 bytes per book (1MB), or around 700GB in text in total in the library. Again let’s assume that a portion of these scrolls contain images, which take up a lot of information not captured by the text alone. That brings us up to the 1TB mark? It’s a nice round number.